In the Guild’s most recent research report, Making mLearning Usable: How We Use Mobile Devices,fieldinvestigators (Guild members and others interested in mobile learning) gatheredobservations on how people touch and interact with tablets such as the iPad,iPad mini, Galaxy Note, and Nexus 7. They sent in 651 observations on amobile-friendly web form from 22 countries about how people use their tablets. Wesimply didn’t have this data before (even though we are developing learning forthese devices)!
This is called crowdsourcing data, and it’s a veryinteresting process that I thought I’d explain in a bit more detail becauseit’s something that you might want to consider doing yourself when you need togather data.
We could have simply asked people how they use theirtablets, of course, but we know that “self-report” data about how people dothings is not as reliable as anonymous observations are. For one thing, peopledon’t always know how they do things and, when asked, may unknowingly changetheir behavior. And, unfortunately, we also know that when asked, people tendto tell you what they think you want to hear. So we decided to ask for helpgetting a lot of observations because we could get more observations this wayand the observations would be far more diverse than anything we could doourselves. (Thank you, field investigators!)
I’d like to discuss some other differences between surveysand crowdsourced observations so you can decide whether you might like to usecrowdsourced observations for gathering data in your organization.
Surveys for gathering data
We often gather data inside organizations by surveyingpeople. But surveys, of course, have their problems. Two big problems are lackof response from some people and response bias.
Most surveys don’t use random samples (because randomsampling requires knowing how to do one and is time consuming and expensive).Not using a random sample introduces response bias, which means that we don’tknow whether the people who did respondanswered the same way as a random sample would have answered. But we also don’tknow how the people who didn’t respondwould have responded. Surveys pretty much ignore response bias because correctingfor it requires surveying non-responders and analyzing the differences inanswers between them and the people who did respond. And getting non-respondersto respond is hard. (Duh.)
Even with random samples, some people are more willing toanswer than others. For example, women are usually more willing to answer than men.And we know that some subgroups are more willing to answer than other subgroupsare. Good survey researchers know their “population,” and then sample andweight the data accordingly to compensate for what they know about thepopulation they are surveying.
All this is complex, so we typically just look for a largeenough sample and hope for the best. But it’s important to realize that somequestions, especially self-reporting questions, are notoriously unreliable. Soif you are asking questions that you could observeinstead, observe! You’ll have muchbetter data!
Crowdsourcing for gathering data
Crowdsourcing data gathering allows you to have a group ofparticipants (workers, customers, etc.) observe what is happening and sendobservations back to you. Actually, you can use crowdsourcing in research in avariety of ways, but I’m pointing out one of the ways you might consider usingit.
For example, let’s say you wanted to find out when the kitchensin your buildings most need cleaning. You could build a web form and ask peopleto fill it out whenever they use a kitchen. Or you could mount an iPad in eachkitchen and post a form (Figure 1).
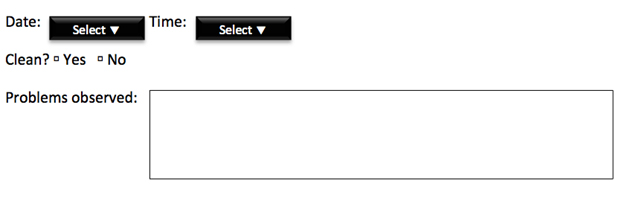
Figure 1: Survey Form: Is the kitchen clean?
This may be a silly example, but asking for realobservations at the point of observationcan be extremely valuable. (Having observers post observations later may forcethem to recall events, which suffers from some of the same problems asself-reporting does. People tend to miss things or embellish.) Many people havesmartphones and tablets and if you post an easy-to-remember URL, people areoften willing to post observations in a short form.
Using outside observers in research isn’t new. Citizenscience (also known as crowdsourced science) is scientific research conducted withhelp from nonprofessional (avocational or public) scientists. For example, CancerResearch UK has recently launched an online interactive database of cancerouscell samples and is asking the public to help their lab researchers by lookingat and spotting cancer cell cores in millions of images (www.clicktocure.net).
So consider crowdsourcing observations when you want to knowwhat’s really going on. Make your observation form clear and concise. Considerhow people will get those observations to you. Anonymous is best.
From the Editor: Want more?
At The eLearning Guild’s mLearnCon 2014 Mobile LearningConference & Expo, Steven Hoober and Patti Shank will present Session 101,“How People Hold and Touch Their Mobile Devices.” In this sessionyou will explore new research from The eLearning Guild that brings to light howpeople use all their different devices in all environments, from the street tothe classroom. You will learn the research findings and synthesize them intoactionable guidelines that you can use to immediately improve the design anddevelopment of your mLearning projects. You will leave this session with anunderstanding of how humans interface with touchscreen mobile devices, and howyou can leverage this information in your mLearning design.