


The Institute for Creative Technologies at the University of Southern California (USC-ICT) is a US Army university-affiliated research center. This center conducts research and development for training across multiple domains including simulations, games, artificial intelligence models, virtual and mixed realities, and more. This article is a case study of learning technology work my organization is doing for USC-ICT.
Among USC’s many programs is one titled Captivating Virtual Instruction for Training (CVIT). A portion of the stated goals of CVIT puts it this way: “CVIT is a multi-year research effort seeking to produce blueprints for mapping effective instructional techniques used in successful live classroom settings to core enabling technologies, which may then be used for the design and development of engaging virtual and distributed learning applications.”
The challenge of creating captivating distance learning
Let me unpack that statement. There is a purposeful focus within CVIT around the word “captivating.” The user experience (UX), the learning experience: Is it captivating? The USC learning and behavior scientists are looking to take the concepts that make popular and effective live training “captivating,” and keep it captivating while digitizing and blending it into distance learning. There is a tremendous value in the training content’s holding your attention and keeping you engaged. This particular content has been designed with learning science, is considered documented training materials or platform instruction, and is deemed to be effective at meeting a standard of performance when delivered by the instructor. Considering that instructor-led training, or ILT, has often been referred to as “death by PowerPoint,” there is good reason to develop examples of captivating distance-learning blueprints.
Badging and achievements
The USC-ICT behavior scientists were looking to take an instructor-led information assurance (cybersecurity) training course, bring the training into the digital realm, and make sure it is captivating. The course title is Intelligence Architecture Online Course (IAOC).
USC reimagined this certification course and included the requirement to deliver different rules or training scenarios based on the seniority and role of the learner. The entire training is estimated to take up to 10 hours for each role. There are several video instruction modules, a video game, assessments, flash cards, and an xAPI-populated learning experience with badging and progress indications (Figure 1 shows the learner portal). Within the courseware framework, IAOC is designed around a simulation game in which the learner is given training tasks to complete in a certain amount of tries. An xAPI-populated learning experience means that the entire UX is populated with data from the learning record store (LRS). A tremendous amount of data is being shared with individuals about where they are in the training and how they are scoring in terms of competency.
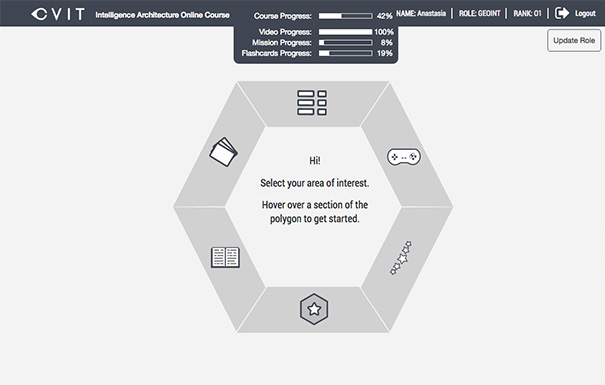
Figure 1: Main learner portal of IAOC
For the most part, this translates to a badging and achievements dashboard (shown later in Figure 4). The interaction data for each video game session is also made available to the user (Figure 2). What’s more, all the training data for all the users in aggregate is available to the instructional designers or scientists, and we are looking forward to seeing how they use it to verify, sustain, and improve this training. USC has access to the raw interaction data in their LRS. They had specific xAPI reporting requirements designed to enhance UX and display in a learner’s view. Additionally, IAOC supports the following two use cases: to be delivered stand-alone by individual course participants, or to be part of an instructor-led course accessed from the classroom. The instructor module supports blended learning (e.g., instructor-in-the-loop). This training also needed to be launched from an institutional LMS (see my prior article, “Remote HTML5 and xAPI Can Work with Your LMS”) and provide authentication access.
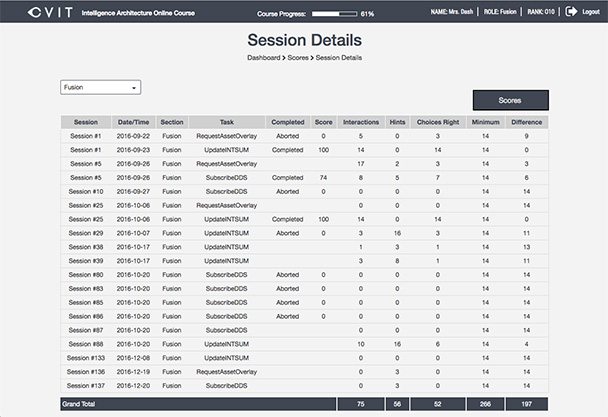
Figure 2: Game mission details to learner based on role
The foundational approach uses an HTML5 courseware (eLearning software) framework that includes both pre-baked xAPI recipes and a method for adding additional xAPI tracking. General concepts such as activity, page, and topic relate specifically to how the eLearning software is set up. A course is made up of one or more topics, and each topic comprises one or more pages. An activity is an interactive section such as a drag-and-drop exercise, scenario, video, or assessment, which is usually on a single page.
The game is created with Phaser.io (an open source framework for HTML5 Canvas and WebGL-powered, browser-based games). Figure 3 shows a game view. Everything is reporting xAPI to the LRS. In the case of the Phaser.io game, we developed what is called an xAPI client or middleware. It is not necessary for every vendor or technical engineer out there to know xAPI in order to get the technology to report xAPI. If the technology can publish messages, it is possible to subscribe to them and convert the messages and data into xAPI.
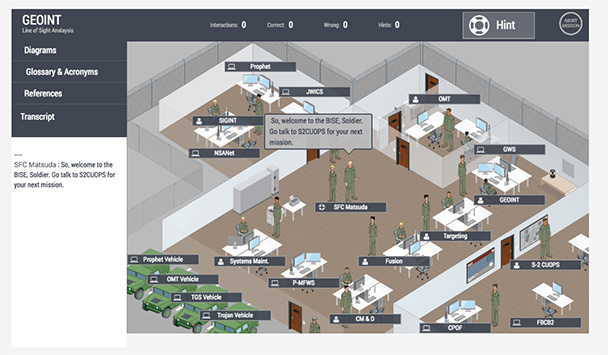
Figure 3: Phaser.io game view of a mission in progress
This is referred to as a publish-subscribe pattern, or pub/sub, and it is a great fundamental to remember when you want to get different software talking xAPI. If you have a pub/sub option available, it removes the need for the proprietary software engineers to understand xAPI—they simply need to publish events. Google Analytics is probably the best example to describe the method. Have you ever used Google Analytics? You just drop a little JavaScript on your HTML page and it works! That little JavaScript is a client. It’s the same concept.
Table 1 provides an example of some of the initial xAPI reporting requirements given by USC.
Table 1: Some of the USC xAPI reporting requirements
|
Metric |
Formula |
Notes |
|
Scenario Score |
# Correct / (# Correct + # Wrong + c * # Hints) |
For a single scenario attempt. c is a constant between 0 and 1, which might be manipulated at the user level (e.g., should be an on-create property for a user). |
|
Scenario Mastery |
Avg (Scenario Score of Last Three Attempts) |
One of these for each scenario. |
|
Role Mastery |
Avg (Scenario Mastery for Scenarios in Role) |
One of these for each role. |
|
Role-Type Mastery |
Avg (Role Mastery of Roles in the Type) |
My Role, Other, or All. |
|
Role Efficiency |
# Correct / (# Correct + # Wrong + c * #Hints) |
For all scenario attempts in a role. |
|
Entity Efficiency |
# Correct and Clicked on Entity / (# Correct and Clicked on Entity + # Wrong) |
For all scenario types, when “entity” was a valid answer. Only consider when “Wrong” or they clicked on “entity” (e.g., don’t count if they clicked other right answers). |
The badging and achievements engine
As mentioned earlier, IAOC is designed around a simulation game in which the learner is given training tasks to complete in a certain amount of tries. The total training focuses on three categories of activities, all using xAPI to track interactions:
- Knowledge—Core IA comprehension (text, interactive diagrams, videos, flash cards).
- Application—Applying knowledge to problem scenarios (game-based learning). This is a video game developed in Phaser.io.
- Evaluation—Causal performance reviews (performance screens based on learning metrics).
xAPI is used to record statements each step of the way, and the HTML5 courseware application displays collections of those statements as learner achievements and badges. USC needed a system of badges and achievements with criteria of actions or successful activities that, when met, “earn the badge.” Once all the badges are earned, the learner is ready to certify (Figure 4).
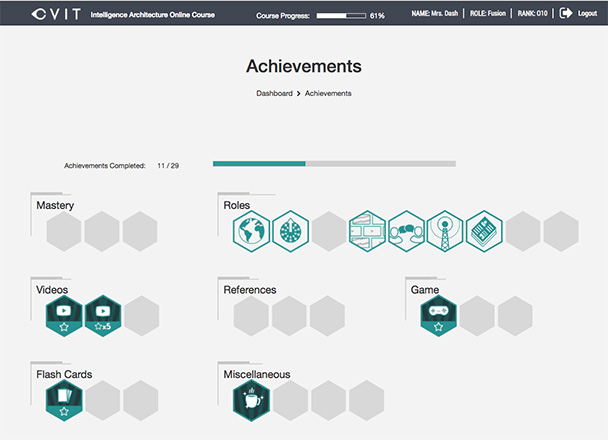
Figure 4: IAOC badging and achievements
Rather than hard-coding the rules for badging, creating an “achievement engine” helped to abstract away the logic into more of a service. We can keep these systems reusable and interoperable when we think this way. For instance, if today one must complete five videos to achieve a video badge, and you as the instructor want to add another step or rule to earn that badge, it should be simple to change the rules for achievements. Multiple instructional use cases point to a badging system or service, and some of these badges can represent core competencies or critical learning paths being achieved. What defines mastery may change. In the case of an achievement engine, we calculate a stream of xAPI activities and results while ensuring it can change according to the learner process models (or business process flows) needed at a given time.
Today’s perceived value of eLearning
Interactive multimedia instruction (IMI) is still a relatively new art and science. Good eLearning requires skills in instructional design, cognitive sciences, media arts, and computer science. Even in the realm of platform instruction, many information-centric page turners provide low learning impact and low business impact—when that kind of information is merely shoveled onto a page, the result is poor eLearning.
I think there is a growing school of thought that is pushing to do away with courseware, or what we can call “traditional” IMI. To me, this is like throwing away the baby with the bathwater. There are affordable, open-source alternatives to Flash that work better in our world today. The rapid pace of technology has now led some to use derogatory terms for interactive page-turning courseware, such as “shovelware” or “data dumps,” as if something along the lines of an interactive textbook that may have all types of media integrated into the UX is a bad thing. The technologies and frameworks available today as tools do not make the smart decisions for us. We need to create and program the tools, and provide the rules for smarter distance learning. As an aside, that is why something like xAPI is so powerful in understanding the result of your instructional design work.
Historically, we have not been able to easily get actionable or historical interaction data from learning products, good or bad. So, I think it is unlikely that using the buzzwords “social learning” and “microlearning” is going to magically fix a problem, if we do not create and publish a decent IMI product in the first place. I am not speaking of the instructional designer who has the whole world upon her shoulders, no budget, no technical tools, and the mandate to just “make it better.” I am trying to talk to her leadership. Also, I do agree that social and microlearning strategies are extremely viable. I work and look for advancements in all of IMI, and I do think real progress is happening in all device-agnostic IMI. Hopefully today, the key to better training ROI is to simply pick the right tools for the job.
The path to adaptive learning and automated tutoring
Looking forward, we can develop logic and rules based on xAPI/LRS data to better serve IMI. We can even begin to adapt to the training event by querying the LRS on behalf of the learner, and/or mining and reacting to user interactions as the data is reporting to the LRS. Remember, the LRS is simply learning-activity-stream data. It holds the statement that the learner “mastered” something, and the stream of activities and verbs it took to get there. If you want to intervene or adapt the training, you can create rules based on xAPI/LRS-captured results.