


In September 2016, The eLearning Guild presented an online Data & Analytics Summit for Guild members worldwide and other interested practitioners. During the two-day event, thought leaders from the data and analytics space explored questions that those in the learning field are struggling to answer. The speakers helped provide clarity around what practitioners are doing today and what they can accomplish in the future with learning analytics.
Our newest white paper, by leading analytics expert and assessment practitioner A.D. Detrick with Sharon Vipond, provides timely information and guidance that supports and extends the ongoing goals we envisioned in the Data & Analytics Summit. This white paper provides practical insights meant to help you make data more actionable within your organization, and to prepare you to take advantage of the new opportunities that data will open up for learning in the future. In this valuable white paper, you will learn about:
- Four types of analytics that are used to describe and distinguish complex data categories
- Six steps that form the learning analytics process
- The importance of creating a clear and comprehensive data impact map before beginning data capture
- Four types of learning analytics that define the basic metrics underlying learning interventions
- Statistical analysis methodologies recommended for learning analytics processes
- The importance of providing an analytical context that helps inform stakeholders of strategic insights contained in data results
- How to avoid common learning analytics pitfalls
- How to use a checklist of “Steps to Success” in learning analytics (this checklist is included with the complete white paper)
Also included are extensive resources from The eLearning Guild and other sources, as well as a glossary of terms, which helps define the terminology discussed within the paper. Let’s now review some of the basic concepts and practical advice presented in the white paper.
The rise of learning analytics
For decades, the learning industry has operated under a simple guiding principle—to provide relevant, applicable, and timely learning. And for much of that time, the industry has measured and refined its efforts with a loose collection of high-level data points. Learning management system (LMS) completion records, satisfaction surveys, and test results have been aggregated and compared to track historical performance. Having access to only broad, high-level data limited the industry’s potential for any insightful analytics, and so learning and development (L&D) stakeholders adjusted their expectations accordingly. But the desire always remained to make learning more relevant, more applicable, and deliver it just in time—a truly personalized learning experience.
Soon after the turn of the century, a massive explosion of digitization and global information storage occurred, and it has continued to grow unabated. The ability to gather and store data efficiently and inexpensively has made large data warehouses a standard investment, often created without any specific plan for how the data will be used. Distributed tech platforms and cloud-based storage of data have made the storage, transfer, and computation of massive amounts of data possible by individual users, not just super-computer owners or business analysts with detailed knowledge of writing SQL queries. And for the first time in history, L&D (and industries like it) began to see vast increases in learner data: data that could be used to provide insights into learner behavior.
More importantly, we began to gain access to business data: sales numbers, productivity metrics, customer satisfaction scores, etc. Business data, once siloed and guarded with fierce territoriality, suddenly expanded so rapidly that data sharing became a more respected commodity than data hoarding. When everyone became a data owner, the need to protect data for the few insights it could yield disappeared. Now, owners could share their data freely to search for meaningful insights in the way different behaviors affected one another.
L&D data owners are no different. In recent years, our access to data has expanded dramatically. No longer are we relegated to an LMS-provided list of course completions per student as the sum total of our efforts. Today, L&D organizations receive data from numerous sources, often in great detail.
- Traditional LMSs have expanded their data-gathering capabilities to include data on user behaviors within courses, as well as detailed information on assessments and surveys administered within the LMS. Many include social collaboration functions that can be tracked closely.
- The rise in Experience API (xAPI) learning record stores (LRSs) allows L&D organizations to not only track any designated learning activity, but also import data from relevant business sources.
- Learning portals and corporate MOOCs now track asynchronous, self-guided learning through microcontent and curated content, where learners can learn through millions of possible permutations.
In a few short years, data has become so available to L&D that we can not only quantify our learning efforts, but now also perform analytics that identify which aspects of learning correlate most strongly with employee performance. Finally, the availability of data—and the reduced uncertainty provided by effective learning analytics—allows L&D departments to create timely, applicable, and relevant learning.
Four types of analytics
The first major step in a learning analytics initiative is the gathering of data—and the more data, the better. However, raw data itself is useless; it is just a bunch of individual pieces of information that need to be aggregated and compared before we can pull insights from it.
But just gathering data randomly, with no forethought or plan, is an unwise start. The goal of any analytics initiative is to identify decisions that will lead to impactful actions. Effective planning will help define which type(s) of analytics you can perform, what questions you will be able to answer, and how much additional input you will need in order to make insightful decisions. In 2014, Gartner defined four categories of analytics: descriptive, diagnostic, predictive, and prescriptive. Each of these four categories (Figure 1) provides insight into the raw data; as the complexity of the analysis increases, less additional input is needed.
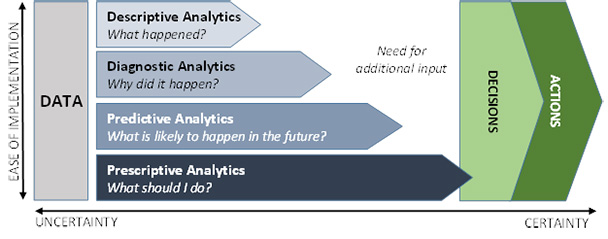
Figure 1: The four categories of analytics (Source: Gartner, 2014)
Descriptive analytics
The simplest, and most basic, form of analytics is descriptive analytics. Descriptive analytics use historical data to tell us what has happened. These analytics usually require the least amount of mathematics to define; an analyst usually needs to know only how to sum or average a set of numbers.
Common descriptive analytics in L&D include count of learners, number of classes completed, and average scores on an assessment. Descriptive analytics provide a hindsight view of our performance. Unfortunately, it is a hindsight view without the benefit of any context, which makes it pretty useless. Without context, it is impossible to know whether our L&D department’s holding 29 classes last week was typical, excessive, or underperforming. And yet, because descriptive analytics are so easy to gather and assemble, many reports in the L&D industry don’t go beyond descriptive analytics.
Diagnostic analytics
Diagnostic analytics provide the context needed in descriptive analytics. Whereas descriptive analytics is concerned with the count or average of a data set, diagnostic analytics is focused on identifying the significance of those events and where they stand in relation to similar events. This context can help organizations identify what has happened, and it can also provide evidence for us to understand why it happened.
Diagnostic analytics require more effort to complete. The common functions of diagnostic analytics are the distributions of outcomes, probabilities, and statistical likelihoods. Building on the work we’ve done in descriptive analytics, we can use diagnostic methodologies to find answers to more relevant questions, such as “Which trainer(s) outperformed their peers on the course?” or “Which location(s) had the highest course completion rates last week?” Diagnostic analysis can tell us what happened, and where that metric stands in relation to other metrics and the significance of that difference.
Predictive analytics
While the previous types of analytics were focused on what has already happened (and why), predictive analytics is focused on what is likely to happen. In the simplest terms, predictive analytics is using previous conditions to make educated assumptions about what is likely to occur in the future. With predictive analytics, we make hypotheses (assumptions) based on sets of quantitative data and how these sets interact with and affect one another. These hypotheses are tested using statistical tests that identify when the relationships between behaviors in different data sets are likely to affect one another. These behaviors are then characterized as “predictive.” Predictive models also include a value that identifies the level of certainty of the prediction; it is important to remember that no analytics can predict with 100 percent certainty, but every statistical test has a threshold that tells us when there is enough statistical evidence to consider the prediction “significant.”
Common examples of predictive analytics used by L&D organizations include regression models, classification models, and Bayesian analyses. These examples require some advanced analytics tests to complete them: t-statistics, AIC (Akaike information criterion), confidence intervals, KS (Kolmogorov-Smirnov) test statistics, p-values, etc. While these tests can all be calculated manually, they are made much easier by available business intelligence (BI) tools, many of which will not only calculate these models but also translate them into plain language.
Prescriptive analytics
Prescriptive analytics is the extension of predictive analytics. If predictive analytics tells us what is likely to happen by finding relationships in the data with very little uncertainty, prescriptive analytics finds the most significant of those events and recommends automated future actions. Prescriptive analytics takes the detailed statistical work of the predictive models and provides guidance around discrete decisions that can be made to ensure positive results.
Say, for example, your prescriptive analytics tested whether learners who viewed at least 10 instructional videos on a learning portal are more likely to achieve higher customer satisfaction scores in the first 90 days. Predictive analysis would find out how likely that is to occur. If the predictive model is able to reduce uncertainty enough, the prescriptive analytics make the decision for us: All learners must watch at least 10 videos on the learning portal.
This is a fairly discrete, simple example. But many of the modern BI tools offer highly sophisticated algorithms (such as neural networks) to locate and characterize these relationships.
The learning analytics process
Performing learning analytics is often confused with data mining, in which analysts query large data sets for trends and common themes that may yield insight. While data mining is effective in specific situations, most L&D departments do not have the volume and depth of data on their own to mine for valuable insight. Instead, learning analytics is a process that benefits from advance planning.
Our newest white paper describes the learning analytics process as consisting of the six phases shown in Figure 2 and further explained in Table 1.
![]()
Figure 2: The learning analytics process flow (Source: A.D. Detrick, 2016)
|
Process Stage |
Description |
|
Hypotheses/Assumptions |
Identify the business goals and measurable objectives of the analytics effort, and map how they will affect one another. |
|
Capture and Clean Data |
Capture the data by different data sources. Clean and normalize those data so they are prepared for proper analysis. |
|
Analyze and Report |
Perform the proper analysis, and report the findings to relevant stakeholders. |
|
Use the Findings |
Ensure the data are presented in such a way that the report will be received properly by the recipient and action will be taken. |
|
Refine Offerings |
Update L&D offerings based on analysis. |
|
Build Supporting Content |
Create supporting content to reinforce the learning. Ensure that content correlates strongly with impact and fills any missing content gaps. |
Table 1: Six phases within the learning analytics process (Source: A.D. Detrick, 2016)
Conclusion
The exponential increase in available data may have been the wellspring that created the opportunities of learning analytics, but its adoption and growth can be attributed to how well it helps define our impact. There is an old adage about analytics that states, “It’s not about the data—it’s what you do with it.” In previous years and earlier L&D incarnations, practitioners could define their usefulness through limited data: the number of classes completed, the number of people trained, and—on occasion—qualitative responses and assessment scores. But the connection between their efforts and the intended results of those efforts was always tenuous, at best. Now, with proper planning and execution, practitioners have access to insights that identify how effectively their efforts have helped transform the organization. They can identify which elements of L&D have significant impact—and which don’t. All of this information can (and should) be used in designing strategies to continually optimize performance by identifying and promoting the elements of L&D that provide the most impact.
That capability should also speak to the heart of all learning leaders. For decades, L&D has tried to distill our available data into simple numbers, to find a calculation that could clarify whether or not our efforts were worthwhile. Learning analytics not only provides this opportunity, it provides it at increasingly more granular levels than we had ever imagined. Today, learning leaders have the opportunity to sit down with organizational stakeholders and provide detailed analyses of which L&D efforts correlate with impact and which don’t. More specifically, learning leaders enter those discussions armed with data to show how L&D has helped engineer behavioral change, and they can then lead discussions with other influencers whose efforts may have had different effects. Instead of taking on the entire burden of behavioral change, learning leaders can use learning analytics to show how learning is creating an impact and to ask other areas (IT, HR, recruiting, front-line management, etc.) to show how their efforts are having complementary or conflicting results.
While learning analytics can, at times, require complex mathematics and assistance from software to complete, the majority of learning analytics work exists in a basic framework that most L&D professionals can manage. Following the framework provided in this white paper can help create a foundation for these efforts, which will allow L&D departments to continually refine and optimize their efforts for greater and greater impact on their organizations.
References
Bosomworth, Danyl. “Micro content – what is it
and how to leverage it.” Smart Insights. 23 March 2014.
http://www.smartinsights.com/digital-marketing-strategy/micro-content-strategy/
Gartner. “Gartner Says Advanced Analytics Is a
Top Business Priority.” 21 October 2014.
http://www.gartner.com/newsroom/id/2881218
University of Wisconsin–Madison. “A Basic
Introduction To Neural Networks.”
http://pages.cs.wisc.edu/~bolo/shipyard/neural/local.html
https://www.elearningguild.com/insights/index.cfm?id=186&utm_campaign=wp-mooc1505&utm_medium=link&utm_source=lsmag