

At Frank Porter Graham Child Development Institute (FPG), a research institute at the University of North Carolina-Chapel Hill, all our learner activity data is gathered in the form of xAPI statements reported to our learning record store (LRS). In this case study, we’ll outline how xAPI supports our instructional design strategy, and what we learned along the way.
About FPG & the learners it serves
Our Institute is an organizational umbrella under which exist many different, grant-funded projects. Research topics include autism intervention, inclusion of disabled children within educational settings, implementation, and scale-up, to name a few. Almost every project engages in some type of professional development or technical assistance for community professionals such as practitioners, educators, or administrators. Goals for training usually include behavior change.
FPG’s challenges
We face several challenges that may be recognizable to learning & development teams in other contexts:
Audiences are external and varied. Projects share neither audience nor data. Furthermore, each project has its own website presence. In some cases, the learners are not already known to the Institute (self-registration). Within this context, an LMS was not a good fit.
How we solved it: Within our learning ecosystem, online learning experiences are portable: they can live on any project website and still report to our LRS.
Meaningful evaluation requires much more data than we can get from SCORM. In order to be useful within a research environment, learner activity data must be conceptually meaningful, reflecting specific learner choices within custom-developed interactions. SCORM data, or even out-of-the-box xAPI from Storyline, doesn’t offer that level of information.
How we solved it: By using xAPI statements, we tailor the learner activity data collected to the needs of each project, creating meaningful variables.
This customization offers a great deal of freedom and ability to implement instructional strategy, leading to well-designed training products and processes. Custom learner activity variables can be correlated with training and research outcomes to assess the effectiveness of not only each lesson and module, but also each interaction within each module. Resulting effectiveness data encourages evolution and is attractive to potential funders, allowing projects better opportunities to access the funds they need to sustain or increase their research teams.
The length and cost to deliver onsite, instructor-led training was burdensome. Many FPG projects would like to lower travel costs that are associated with onsite instruction. Doing so requires onsite instruction to be more effective in a shorter period of time.
How we solved it: The customized data possible with xAPI allows us to implement strategic blended learning design.
Onsite lessons utilize robust, personalized data captured through our pre-work eLearning modules, allowing onsite support providers to review, extend, enhance, or skip areas depending on existing learner knowledge. This data-forward blended learning strategy maximizes the effectiveness of onsite work.
Budget limitations required a lightweight ecosystem. Although FPG projects require technically complex data and accompanying analyses, they are limited by the constraints of grants. There is no budget for project-specific technology infrastructure.
How we solved it: We leveraged the Articulate Storyline licenses we already had, established an account with a low-cost LRS, and worked with consultants to support custom JavaScript development to get us started with an ecosystem that would serve all projects.
How does this system work?
To capture learner activity data, the Institute’s Storyline developers use xapi.ly and custom JavaScript to create triggers that send xAPI data on a variety of screen actions to our SCORM Cloud Learning Record Store (LRS). We ensured that we were using consistent terminology, to better serve reporting now and in the future. JavaScript files provide the xAPI statement elements for each course including actor, verb, and activity information (which includes definitions for custom variables). The actor information is pulled from the module login (embedded in an index.js file) (Figure 1) This file is referenced by the story.html published output file.
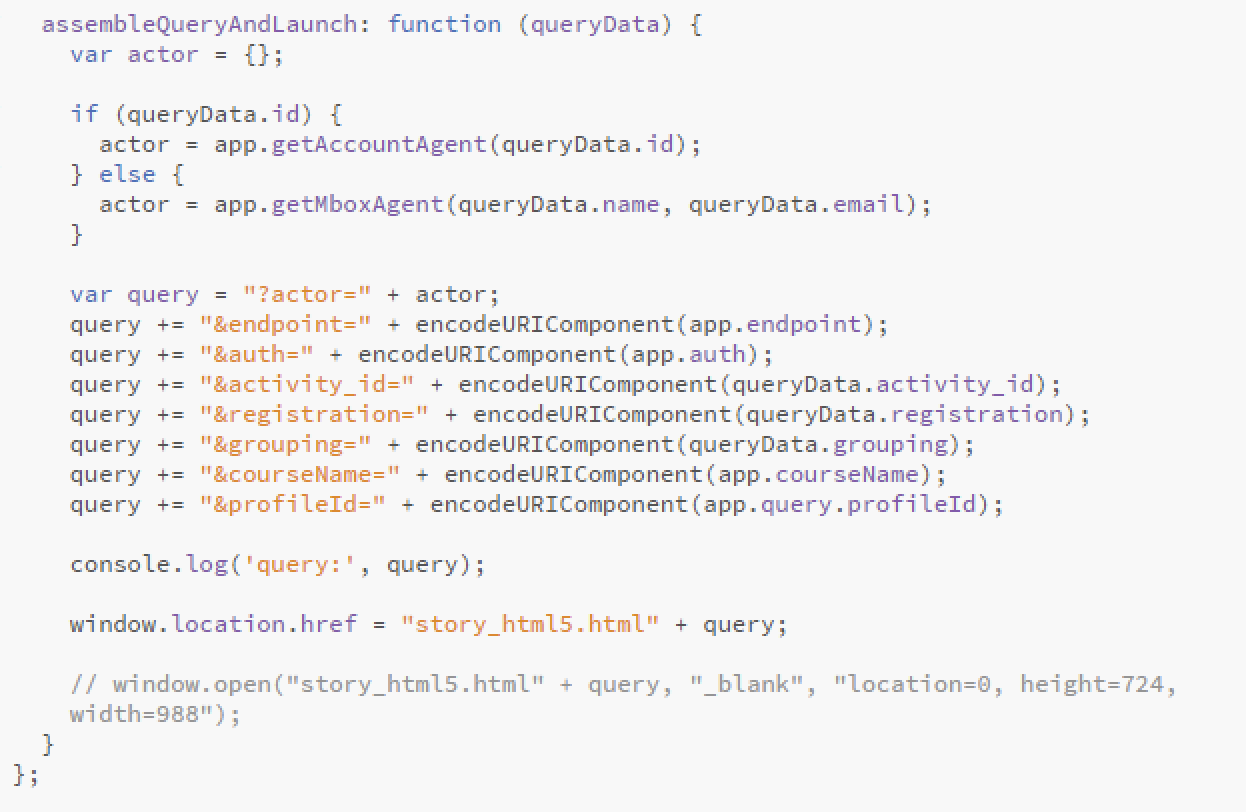
Figure 1: Actor information in index.js file
The verb and activity are defined within a separate functions.js file, referenced by the story.html published output file. (Figure 2)

Figure 2: Verb and activity information in functions.js file
We started by planning the data needs from each interaction for each objective. Here is a page from one project’s planning sheet, outlining 20+ custom-developed learner interactions that are summed into six categories. (Figure 3)
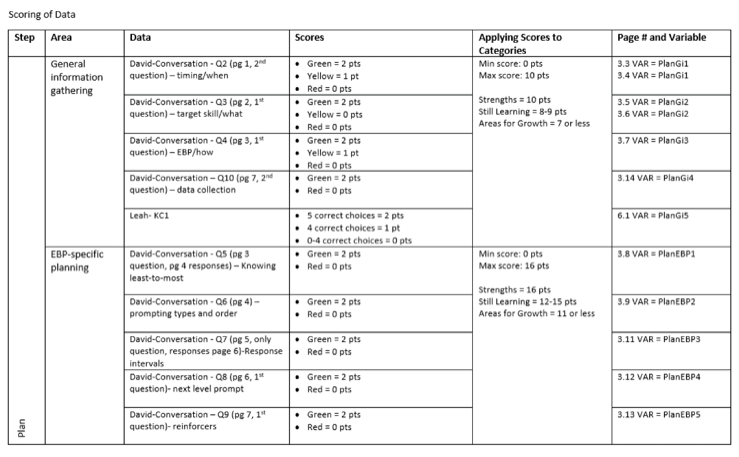
Figure 3: Learner interaction categories
Trigger panel showing the variables summing together in Storyline. (Figure 4)
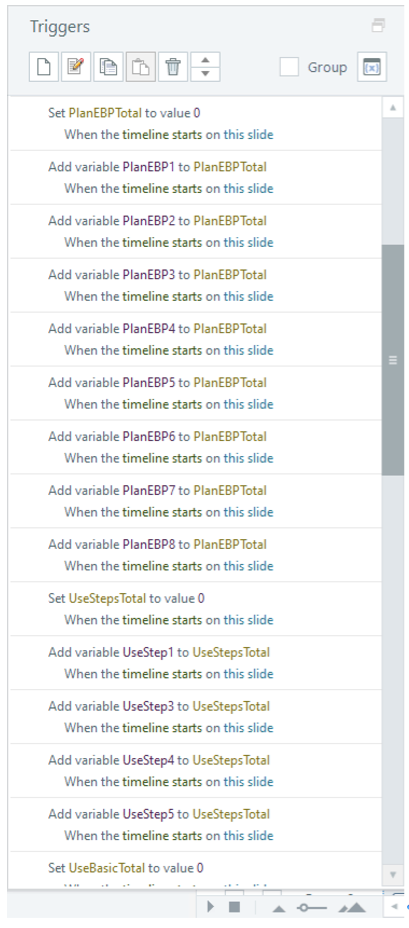
Figure 4: Trigger panel for Storyline variables
Some JavaScript in the associated functions.js file. (Figure 5)

Figure 5: Functions.js file for some of the Storyline variables
Figure 6: Collecting user information
We use SCORM Cloud as our LRS because it is inexpensive. It doesn’t provide exports, so we created a custom query page that allows project-specific data export. (Figure 7) It also does not offer data visualization, but that’s not a problem for us; our statisticians and researchers prefer to analyze and interpret their own data.
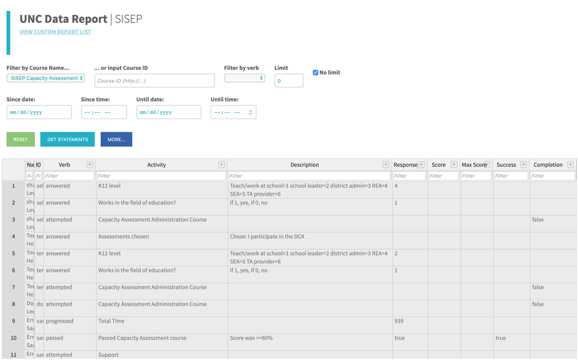
Figure 7: Project web query & data
We also created custom reports to meet the needs of different projects. (Figures 8 and 9)
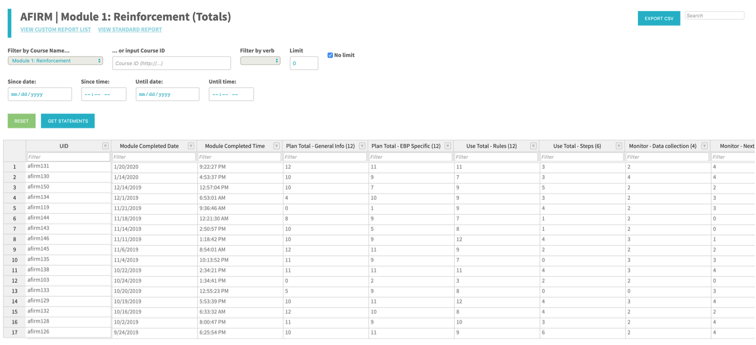
Figure 8: Example of custom report for a project
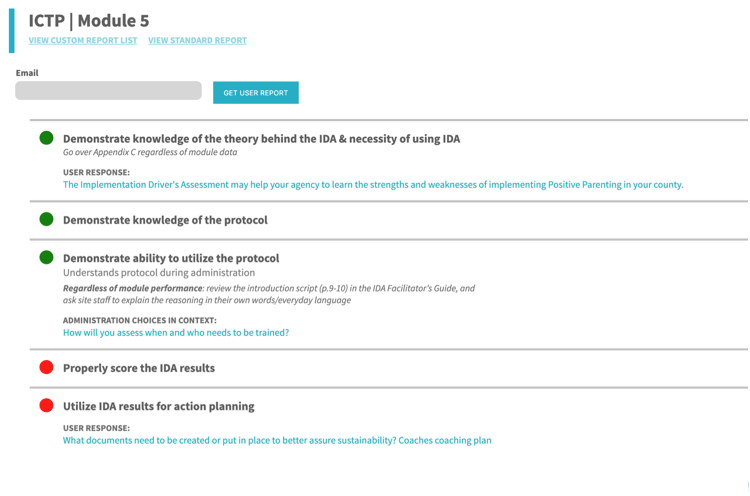
Figure 9: Example of custom report for a project
Lessons you can learn from
Our ecosystem is still fairly new and we are learning important lessons along the way. Here are a few takeaways:
- The measurable alignment of instructional design strategy with research/project goals is incredibly valuable. We know that thinking deeply about goals and essential elements leads all the following work, but it can sometimes feel thankless. When correlated with measured behavior change, xAPI data provides reward with clear evidence for the effectiveness of good strategy and design.
- The ability to collect any kind of data you want can result in a lot of data; it is important to have a clear strategy. Plan your analyses ahead of time so that you aren’t buried in an avalanche of numbers, trying to make sense of it all. What data do you really need, and why? Then, how will you present it to the consumers of data?
- Complex data collection requires detailed quality assurance that data is reporting accurately. Make sure to account for this time after development and assign roles for both content and technical QA—these might be different people.
- Leverage existing data profiles wherever possible so you don’t need to re-invent the wheel and your projects are interoperable with future work all based on the same data model.
- Clients/project staff may need training before the project begins regarding what is possible in terms of module development and data collection. As the project is winding down, they may need training regarding how to access their data.
- As our quantity of projects, modules, and users has scaled (and will scale to potentially over 100,000 users), we’ve found that we may need more advanced reporting, analytics and data export options than was required initially.
Authors' note about funding and support
Funding for the Implementation Capacity for Triple P Projects, including the development of online learning modules, is provided by The Duke Endowment and North Carolina Department of Health and Human Services, Division of Social Services. Support for the development of the AFIRM for Para work came from Grant R324A170028, funded by the Institute of Education Sciences (IES). Support for State Implementation & Scaling-up of Evidence-based Practices Center (SISEP) work came from cooperative Grant H326K17003-SISEP, funded by the Office of Special Education Programs (OSEP). IES and OSEP are part of the US Department of Education, but the contents of this article do not necessarily reflect or represent the policy of that department.
All Contributors


